
At this year’s OFC conference, discussions around optical interconnects in AI scenarios—particularly for scale-out and scale-up architectures—were exceptionally active. Dozens of related workshops and panel discussions took place (as shown in the image below). Interestingly, some experts presented the same slides in different sessions, repeating their points despite differing stances, which made for an engaging dynamic. Here’s a curated summary of key insights for your reference.
With the development of large AI models, compute demand is increasing 100-fold every two years. However, the performance growth of individual GPUs lags behind: GPU compute power increases only 3.3x every two years, memory bandwidth 1.4x, and electrical interconnect bandwidth also 1.4x. As a result, the industry is turning to “superpods”—clusters of multiple GPUs—as a new compute unit, which then scale into AI clusters. Efficient data exchange within and between nodes has thus become a critical challenge, with optical interconnects playing an irreplaceable role.
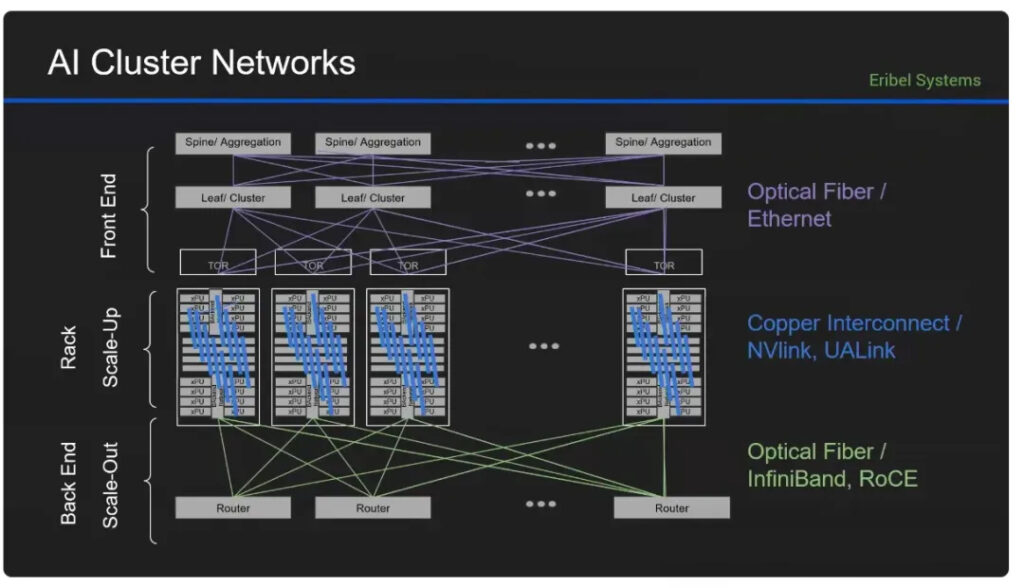
The typical AI cluster architecture is illustrated below. Interconnects between supernodes correspond to the scale-out (or front-end) network and resemble traditional data center architectures. Many supernodes form large AI clusters—up to tens or hundreds of thousands of GPUs. Given the distance of tens of meters to kilometers, scale-out networks primarily rely on pluggable optical modules. Nvidia has also introduced a CPO (Co-Packaged Optics) switch solution this year. In contrast, scale-up (or back-end) interconnects are currently copper-based, connecting GPUs within a single node with high bandwidth and low latency. However, as speeds increase and racks scale up, optical solutions may become necessary. For instance, Nvidia’s NVL72 system uses 72 B200 GPUs and 18 NVSwitch chips connected via 5,182 copper cables to enable full GPU interconnectivity.
Switch and optical module bandwidths are rapidly evolving. Switches now support up to 512 lanes at 200 Gbps per lane, achieving 102.4 Tbps total—doubling every two years. Optical modules double their bandwidth roughly every four years. To bridge this mismatch, optical channel counts are increased.
There are two main ways to expand channel count: more wavelengths or more fibers. As previously discussed in our article [“Bandwidth Scaling in AI Interconnects: More Wavelengths or More Fibers?”], scale-out networks benefit more from increased fiber count due to high radix requirements. However, more fibers also introduce fiber management challenges.
As AI clusters scale, interconnect power consumption becomes a concern. In a 100,000-GPU cluster, optical modules alone may consume up to 40 MW. To reduce this, solutions like LPO (Linear Drive Pluggable Optics) and CPO are gaining traction. These approaches eliminate DSP chips in modules and use ASIC SerDes to directly drive optical engines, reducing overall power usage.
In scale-up networks, copper cables currently consume 4–5 pJ/bit at 200 Gbps/lane, with distances limited to under 2 meters—restricting scalability. For optical solutions to replace copper, energy efficiency must reach below 5 pJ/bit and bi-directional bandwidth density must exceed 2.5 Tbps/mm. Currently reported figures: LPO ~10 pJ/bit, Broadcom CPO ~7 pJ/bit, Nvidia CPO ~5.6 pJ/bit. Thus, multi-wavelength microring-based CPOs may represent the ultimate solution.
Parallel processing across thousands of GPUs means that any component failure can have significant impact. Thus, AI interconnects require extremely high optical engine reliability. Meta, for instance, categorized failures during 54 days of Llama3 training: 58.7% were GPU failures, while 8.4% were network-related.
Common causes of pluggable module failures include PCB defects, wirebonding issues, optical port contamination, and firmware bugs. High reliability demands stringent quality control during production and assembly. Compared to pluggable modules and LPO, CPO—due to wafer-level integration and fewer connection points (1 vs. 6)—reduces potential failure risks. Known-good-die testing before packaging ensures optical engine functionality. Separating the laser module also enhances maintainability. Nvidia claims a 10x improvement in network resilience with their CPO switches.
Typical interconnect cost targets for AI clusters are around $0.1/Gbps, while pluggable modules currently cost about $0.5/Gbps—still a significant gap. Few workshops discussed cost in depth. However, VCSEL-based CPO solutions (being developed by Lumentum, Coherent, Furukawa, etc.) may offer cost advantages for scale-up networks.
To summarize, optical interconnects for AI require high bandwidth, bandwidth density, low power, high reliability, and low cost. In real deployments, trade-offs are inevitable; optimizing all dimensions simultaneously is challenging. Nonetheless, optics have clear advantages in bandwidth and distance, and are poised to replace copper in scale-up networks. Copper solutions, however, are also evolving (e.g., CPC – Co-Packaged Copper). In scale-out networks, pluggable optics will likely remain dominant in the short term.
Will CPO enter scale-up networks sooner than expected? Nvidia aims to double GPU bandwidth every two years and increase scale-up GPU counts by 2–4x every two years—driving rapid optical interconnect evolution. Ultimately, the booming AI industry is pushing optical interconnects forward, making them a vital part of the AI infrastructure and essential to delivering stable, high-speed data pipelines
If you want to know more about us, you can fill out the form to contact us and we will answer your questions at any time.
We use cookies to improve your experience on our site. By using our site, you consent to cookies.
Manage your cookie preferences below:
Essential cookies enable basic functions and are necessary for the proper function of the website.
These cookies are needed for adding comments on this website.
These cookies are used for managing login functionality on this website.
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Google Analytics is a powerful tool that tracks and analyzes website traffic for informed marketing decisions.
Service URL: policies.google.com (opens in a new window)
Clarity is a web analytics service that tracks and reports website traffic.
Service URL: clarity.microsoft.com (opens in a new window)
You can find more information in our Cookie Policy and Privacy Policy for ADTEK.