
The last couple of months there has been a lot of noise about the expected boom of 400Gb, 800Gb and 1.6Tb in the next 2-3 years. Yet it seems only yesterday we made the jump of 40Gb to 100Gb. Similar with latency where requirements increased from us to ms, yet latency in some of my latest project, related to the gateways to the cloud, was in ms. And I thought we were quite advanced in these things, was I so wrong or behind in my assumptions?
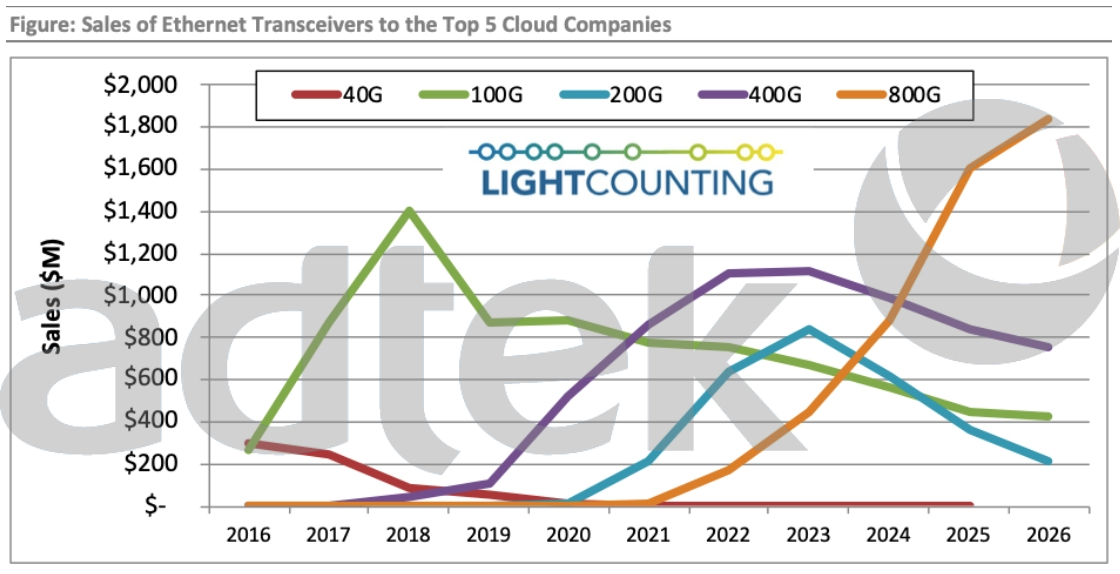
Figure 1: 2021 Lightcounting study on transceiver speed market growth
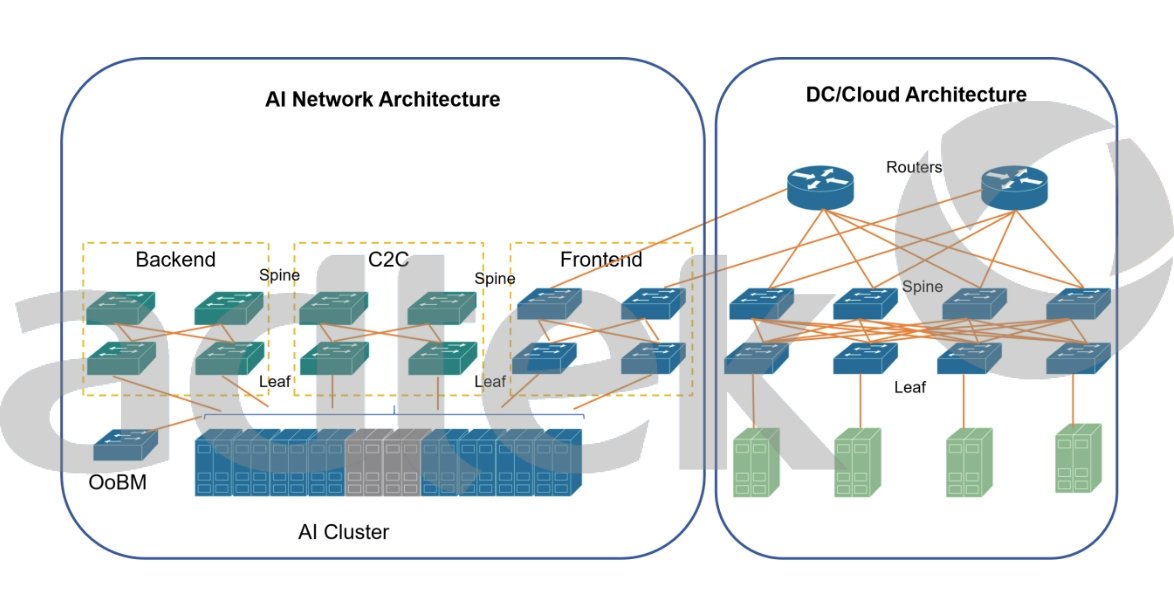

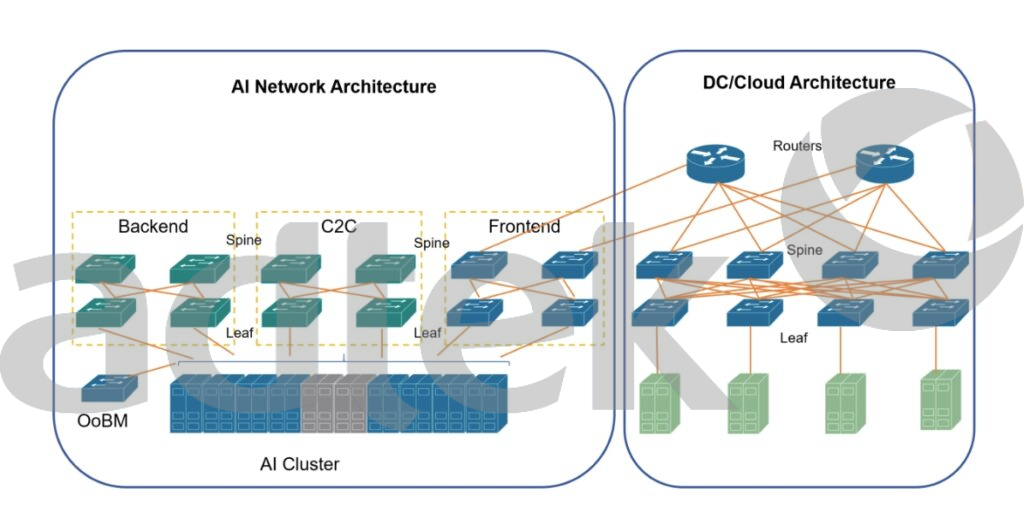
So yes you have to start thinking in your structured cabling design about has to migration to 800Gb and above, but don’t expect a shock change in the next 2 years, this will follow probably the same time trajectory as the previous generations. Which structured cabling supports which data center speeds, how a AI network architecture looks like and much more will be covered in our DC Handbook which we will release in a few weeks.